




robots.txt فایلی است که به رباتهای موتورهای جستجو میگوید که چه صفحات یا بخشهای خاصی از یک وب سایت را بررسی نکنند و مجاز به بررسی چه صفحاتی هستند. اکثر موتورهای جستجوی بزرگ از جمله گوگل، بینگ و یاهو وقتی به صفحات سایت ما سر میزنند ابتدا نگاهی به قوانینی که در فایل ربات سایتمان مشخص کردهایم میاندازند و سپس با توجه به این قوانین به سراغ صفحات سایت ما میروند.
به کمک قوانینی که در فایل ربات سایت مشخص میکنیم، میتوانیم بودجه خزش سایت، منابع هاست و سرور و حتی فراتر از آن، سئو سایتمان را به کلی دگرگون کنیم، اهمیت این فایل در سئوی سایت به قدری زیاد است که یک اشتباه کوچک در آن میتواند به کلی یک وبسایت را نتایج گوگل حذف و ناپدید کند!
در این مقاله به بررسی کامل فایل robots.txt، اهمیت آن، تاثیر فایل ربات بر روی سئو سایت، آشنایی با دستورات این فایل، نحوه ساخت فایل robots.txt و اشکال زدایی و بهینه سازی آن میپردازیم و خیالتان را راحت میکنیم که با خواندن این مقاله از مطالعه هر مقاله دیگری درباره robots.txt بی نیاز خواهید شد.
بگذارید از اینجا شروع کنیم که این فایل دقیقا چیست و چه وظایفی را بر عهده دارد.
فایل robots.txt چیست؟
فایل robots.txt که به عنوان استاندارد یا پروتکل محرومیت رباتها (robots exclusion protocol) هم شناخته میشود، یک فایل نوشتاری با پسوند txt است (در جلوتر خواهیم دید که حتی میتوان این فایل را به صورت مجازی هم ایجاد کرد) که برای خزندهها یا همان رباتهای موجود در دنیای اینترنت خط مشیهای بخصوصی را برای بررسی یک وبسایت مشخص میکند.
برای درک بهتر نقش فایل ربات در سایت، علائم راهنمایی و رانندگی را در ذهنتان تجسم کنید.
عبور از چراغ قرمز مجاز نیست، پارک در محلهایی پارک ممنوع، غیرمجاز است و … قوانینی که چون در آیین نامه راهنمایی و رانندگی تعریف شدهاند باید توسط رانندگان هم رعایت شوند.
فایل robots.txt هم دقیقا مانند آیین نامه راهنمایی رانندگی برای رباتها و خزندههای دنیای اینترنت عمل میکند. به کمک این فایل ما میتوانیم محدودیتهایی را در خزش رباتها تعیین کنیم و انتظار داشته باشیم که آنها هم به این محدودیتها پایبند باشند.
اکثر خزندههای موتورهای جستجو بزرگ مانند گوگل، بینگ و یاهو به محدودیتهای تعریف شده در فایل ربات سایت احترام میگذارند. اما متاسفانه دقیقا همانطور که برخی از رانندگان از قوانین راهنمایی و رانندگی سرپیچی میکنند و به قوانین و محدودیتها احترام نمیگذارند، در دنیای اینترنت هم برخی از رباتها به محدودیتهای تعیین شده در فایل ربات کاری ندارند و هرطور که دلشان میخواهد سایت ما را خزش و بررسی میکنند.

اما به صورت کلی میتوانیم امیدوار باشیم که تمام قوانینی که داخل فایل ربات سایتمان مشخص میکنیم توسط مهمترین خزندههای وب یعنی خزندههای گوگل رعایت میشوند.
حالا که تا حدودی متوجه شدیم که کلیت این فایل چیست، بد نیست که نگاهی به نقشهای فایل robots.txt و دلایل اهمیت آن بپردازیم و دقیقا مشخص کنیم که چرا سایتمان باید حاوی فایل robots.txt باشد.
آیا تمام سایتها به فایل robot نیاز دارند؟
قبل از اینکه به دلایل اهمیت این فایل بپردازیم، باید بدانید که در صورتی که خزندههای وب نتوانند فایل robot سایت شما را پیدا کنند، با این فرض که صاحب سایت هیچگونه محدودیتی برای خزش این وبسایت در نظر نگرفته است، به صورت پیشفرض و بدون در نظر گرفتن هیچگونه محدودیتی، شروع به خزیدن وبسایت شما میکنند و در این خزشها ممکن است اطلاعاتی را پیدا کنند که خیلی خوشآیند شما نیست و دوست ندارید که این اطلاعات مثلا توسط موتورهای جستجو در صفحه نتایج به نمایش دربیایند.
علاوه بر اینها، حجم زیادی از ترافیک و منابع هاست و سرور ما هم صرف پاسخگویی به رباتها میشود که بسیاری از این درخواستها بدون سود و تنها مضر هستند و الکی منابع سایت ما را هدر میدهند.
بنابراین دقیقا همانطور که در بیشتر سایتهای بزرگ برگهای تحت عنوان قوانین و مقررات برای کاربران سایت وجود دارد، در همان ابتدای شروع به کار سایت هم، ما باید قوانین و مقررات مخصوص رباتها را برایشان مشخص کنیم که در آینده برایمان دردسر درست نکنند!
چرا فایل robots.txt انقدر مهم است؟
همانطور که متوجه شدید، اگر فایل رباتی در کار نباشد، خزندههای موتور جستجو گوگل سرشان را میاندازند پایین و هرچیزی که جلو دستشان برسد را بررسی میکنند.
اما این چیزی نیست که ما دنبال آن باشیم، بنابراین باید بتوانیم به کمک فایل robots قوانینی را مشخص کنیم که باب میل ما هستند.
جلوگیری از نمایش صفحات غیر عمومی سایت
تقریبا در تمام سایتها، بخشهایی وجود دارند که معمولا صاحبان سایتها علاقهای به بررسی این بخشها توسط خزندههای گوگل ندارند و یا حتی فراتر از آن، برخی از بخشهای سایت مانند محتواهای عضویت ویژه، صفحات مدیریت سایت و … اگر در نتایج گوگل یا سایر موتورهای جستجو پیدایشان شود ممکن است که کار دستمان بدهند و حتی امنیت وبسایتمان را به خطر بیاندازند.
در این حالت، برای جلوگیری از نمایش صفحاتی که علاقهای به نمایش آنها در نتایج گوگل نداریم از فایل robots.txt کمک میگیریم و آدرس این گونه صفحات را از دسترس خزندههای گوگل خارج میکنیم.
البته بهتر است برای اطمینان بیشتر و جلوگیری صددرصد از ایندکس اینگونه صفحات از تگ noindex هم استفاده کنیم که در جلوتر به صورت مفصل به آن خواهیم پرداخت.
مدیریت بهینه بودجه خزش سایت
موتور جستجو گوگل به تجربه کاربری سایتها توجه ویژهای دارد، یکی از مواردی که به تجربه کاربری کاربران لطمه زیادی وارد میکند بحث از دسترس خارج شدن سایت یا به اصطلاح down شدن آن است.
همانطور که گفتیم، هاست و منابع سرور سایت ما برای پاسخ دادن به درخواستهای رباتها دقیقا همانند پاسخگویی به درخواستهای کاربران واقعی مشغول میشود. وقتی این درخواستها از حد توان سرور سایت ما خارج شوند اتفاق از دسترس خارج شدن سایت رخ میدهد.
گوگل که به خوبی از این موضوع آگاه است، برای اینکه به تجربه کاربری سایتها کمترین لطمه را وارد کند برای هر سایت یک بودجه خزش (Crawl Budget) مشخص در نظر میگیرد و با توجه به فاکتورهای مختلفی این بودجه را کم یا زیاد میکند.

اگر نسبت به این موضوع هیچ اطلاعاتی ندارید ویا علاقهمند آشنایی و درک بهتر موضوع فوق العاده مهم بودجه خزش هستید حتما مقاله “بودجه خزش سایت چیست” را با دقت مطالعه کنید.
با توجه به محدود بودن این بودجه برای هر سایت، طبیعتا نباید اجازه دهیم بودجه خزش سایت ما صرف خزش محتواهایی از سایتمان شود که هیچ کمکی به افزایش ترافیک سایت ما نمیکنند.
به عنوان مثال در بسیاری از سایتها بخشی تحت عنوان پروفایل کاربران وجود دارد که نمایش این پروفایلهای کاربری در نتایج گوگل هیچ ترافیکی برای سایت مورد نظر ایجاد نمیکنند.
اگر شما هم در سایتتان از اینگونه صفحات دارید، یکی از ابتداییترین اقدامات بلاک کردن دسترسی رباتهای گوگل به اینگونه صفحات به کمک فایل robots.txt است تا زمان با ارزش رباتها صرف خزش و ایندکس محتواهای با ارزشتر و مفیدتر سایت شما شود.
محدود کردن ایندکس فایلهای خاص
استفاده از متا تگهایی مانند noindex اگرچه در جلوگیری از ایندکس شدن صفحات وبسایتها به خوبی عمل میکنند اما متاسفانه برای جلوگیری از ایندکس منابع خاصی مانند فایلهای PDF، تصاویر، ویدیوها و سایر فایلها نمیتوان از اینگونه تگها استفاده کرد.
در حالت نقش robot.txt به خوبی مشخص میشود. به کمک دستورات فایل ربات، به راحتی میتوانیم از ایندکس شدن و نمایش اینگونه فایلها در نتایج موتورهای جستجو جلوگیری کنیم.
حذف کامل یک صفحه از نتایج گوگل به کمک فایل robots.txt
همانطور که تا اینجا متوجه شدید، برای حذف کامل یک فایل خاص مانند فایلهای PDF یا تصاویر از نتایج گوگل، میتوان به کمک محدودیتهای فایل robot اینکار را به صورت کامل انجام داد.
اما در مورد حذف کامل صفحات از نتایج گوگل چطور؟
گوگل صراحتا اعلام کرده که تنها محدود کردن URLها و صفحات در فایل robots.txt منجر به حذف کامل صفحات سایت از نتایج گوگل نمیشود، چرا که ممکن است خزندههای موتور جستجو گوگل به کمک لینکهای یک صفحه و انکر تکستهای آن به سراغ آن بروند و آن را ایندکس کنند.
در این حالت یکی از راه حلهای پیشنهادی گوگل، استفاده از تگ noindex در هدر صفحه مورد نظر است.
برای حذف کامل صفحات از نتایج گوگل به جای فایل robots.txt از تگ noindex استفاده کنید
به کمک متا تگ noindex در هدر یک صفحه میتوان امیدوار بود که این صفحه به صورت کامل از نتایج گوگل حذف خواهد شد. برای اینکار کافیست در هدر صفحه مورد نظر به صورت زیر عمل کنید.
<!doctype html>
<html>
<head>
<meta name="robots" content="noindex" />
(...)
</head>
<body>
(...)
</body>
</html>
با اینکار خزندههای موتور جستجو گوگل حتی اگر فایل robots.txt سایت شما را هم نادیده بگیرند چون در داخل صفحه صراحتا از رباتها خواسته شده که این صفحه را ایندکس نکنند، به این درخواست احترام میگذارند.
آشنایی با انواع رباتهای خزنده اینترنت
در دنیای اینترنت، بیش از هزاران نرم افزار برنامه نویسی شده برای خزیدن داخل وب وجود دارند که به آنها رباتهای خزنده یا crawler گفته میشود.
شرکتهای مختلف با اهداف متفاوتی اقدام به ساخت و استفاده از این رباتها میکنند. به عنوان مثال شرکتی مثل Ahref برای بررسی لینکهای موجود در اینترنت، رباتهای مخصوصی طراحی کرده که وظیفه آنها بررسی لینکهای ورودی و خروجی سایتهاست تا به این ترتیب بتواند تحلیلها و اطلاعات جامعی را در اختیار مشتریان خود قرار دهد.
یا حتی بسیاری از سایتهای کوچکتر مثل سایتهای خبرخوان و اصطلاحا تجمیع کننده (Aggregator) هم به کمک رباتهای مخصوصی که در داخل وب دارند میتوانند سریعتر از هر فرد دیگری از انتشار مطالب داخل سایتهای مختلف باخبر شوند و بلافاصله اقدام به انتشار مجدد مطالب داخل سایت خودشان کنند.
گوگل هم به انواع مهمترین موتور جستجو دنیا، چندین ربات مخصوص و مهم برای بررسی صفحات و اطلاعات موجود در اینترنت طراحی کرده است که با توجه به اهمیت آنها به صورت ویژه آن را بررسی میکنیم.
رباتهای گوگل
موتور جستجوی گوگل رباتهای مختلفی دارد که هرکدام وظیفه خاصی دارند، شناخت این رباتها به ما کمک میکند تا ارتباط بهتری با آنها برقرار کنیم و به صورت خیلی دقیقتری بتوانیم فایل ربات سایتمان را طراحی کنیم.
در لیست زیر اسامی مهمترین رباتهای گوگل را برایتان جمع آوری کردهایم:
- Googlebot – این ربات مهمترین ربات گوگل و همان رباتی است که صفحات موجود در اینترنت را پیدا و بررسی میکند
- Googlebot-Image – وظیفه این ربات پیدا کردن تصاویر موجود در اینترنت است
- Googlebot-Video – ربات ویدیو هم برای بررسی ویدیوهایی که در اینترنت منتشر میشوند طراحی شده است
- Googlebot-News – ربات خبری گوگل هم مسئول پیدا کردن مهمترین اخبار در سطح وب است
- AdsBot-Google – این ربات اما مخصوص سرویس تبلیغات گوگل است و صفحات مختلف را به منظور اهداف تبلیغاتی بررسی میکند
علاوه بر اینها، گوگل رباتهای مختلف دیگری را هم دارد که لیست کامل نام و وظیفه آنها را میتوانید در مقاله “مرور خزندههای موتور جستجو گوگل” که توسط خود گوگل منتشر شده است ببینید.
هرکدام از این رباتها با توجه به شناختی که از سایت ما پیدا میکنند با نرخ مشخصی به نام “Crawl Budget” به سایتمان سر میزنند و تغییرات آن را بررسی میکنند.
به کمک فایل robots.txt میتوانیم دقیقا مشخص کنیم که کدام یک از این رباتها به کدام بخشهای سایت اجازه دسترسی دارند و کدام یک باید دارای محدودیتهایی برای بررسی سایتمان باشند.
در ادامه به بررسی مهمترین دستوراتی میپردازیم که به کمک آنها میتوانیم برای رباتهای مختلف قوانین بخصوصی را برای بررسی سایتمان مشخص کنیم.
مهمترین دستورات فایل ربات و نحوه استفاده از آنها
همانطور که گفتیم فایل ربات سایت یک استاندارد همگانی برای مشخص کردن محدودیتهای خزیدن (Crawl) رباتهای مختلف در سطح وب است، بنابراین انتظار میرود که از دستورات استاندارد و همگانی هم برای این فایل استفاده کنیم.
اگرچه برخی از رباتها به دستورات موجود در این فایل توجهی نمیکنند. اما خوشبختانه برخلاف این عده خاص، بسیاری از خزندههای مهم سطح وب به این قوانین و دستورات احترام میگذارند و از آنها پیروی میکنند.
مهمتر از همه اینکه رباتهای گوگل به خوبی با این استاندارد آشنا هستند و از دستورات آن هم پیروی میکنند.
بنابراین برای تهیه یک فایل robots.txt مناسب و عالی ما نیز باید با این دستورات و نحوه تفسیر آنها توسط رباتها آشنا باشیم.
اگر نگران یادگیری این دستورات هستید، باید خیالتان را راحت کنم، چرا که این دستورات خیلی خیلی سادهتر از تصورتان هستند و در کل تنها با 4 دستور زیر به راحتی میتوانیم تمام اقدامات مورد نیاز در فایل robots.txt را انجام دهیم.
- User-agent: برای مشخص کردن رباتی که میخواهیم به دستورات توجه کند
- Disallow: برای مشخص کردن بخشهایی که ربات مورد نظرمان نباید آنها را بررسی کند
- Allow: برای مشخص کردن بخشهایی که مشاهده آنها برای رباتها مجاز است
- Sitemap: برای نشان دادن آدرس نقشه سایت به رباتها
دستور User-agent
در اوایل مقاله با انواع رباتها و خزندههای سطح وب آشنا شدیم، حتی به صورت دقیقتر اسامی و وظیفه مهمترین رباتهای گوگل را هم بررسی کردیم. حالا به کمک دستور User-agent میتوانیم مشخص کنیم که دستورات ما دقیقا توسط چه رباتی باید اجرا شوند.
به عنوان مثال اگر بخواهیم به ربات تبلیغات گوگل دستور بدهیم، به این صورت عمل میکنیم:
User-agent: AdsBot-Google
ربات AdsBot-Google گوگل با دیدن این دستور متوجه میشود که باید از قواعد خاصی پیروی کند و دستورات نوشته شده در فایل ربات مخصوص او هستند.
یا یک مثال دیگر، فرض کنید میخواهید به ربات اصلی گوگل دستور دهید که صفحه خاصی را بررسی نکند، در این حالت به این صورت عمل میکنیم:
User-agent: Googlebot
به این ترتیب ربات Googlebot که اصلیترین ربات گوگل است متوجه میشود که باید به دستورات خاصی توجه کند.
اما شاید این سوال برایتان پیش آمده باشد که اگر دستوری داشته باشیم که بخواهیم تمام رباتها از آن پیروی کنند باید دانه به دانه اسم آنها را صدا بزنیم؟
برای جواب این سوال یک راه حل ساده وجود دارد و آن هم استفاده از علامت * است، به این مثال دقت کنید:
User-agent: *
با اینکار در حقیقت اعلام میکنیم که تمام رباتها مد نظر ما هستند و تمام رباتها باید به دستورات ما توجه کنند و دیگر نیازی نیست اسامی تک تک رباتها را بنویسیم.
همچنین اگر کنجکاو شدید که از اسامی معروفترین خزندهها و رباتهای دنیای اینترنت باخبر شوید، میتوانید دیتابیس اسامی رباتها را مشاهده کنید.
دستور Disallow
در مرحله دوم، بعد از اینکه مشخص کردیم دقیقا با چه رباتی طرف هستیم، حالا باید مشخص کنیم که محدودیتهای این ربات چیست و چه صفحات و منابعی از وبسایت شما را نباید بررسی کند.

بگذارید برای درک بهتر موضوع یک مثال بزنیم،
فرض کنید که در وبسایتتان فولدری به نام mypic دارید که در آن یکسری تصاویر را نگهداری میکنید که علاقهای ندارید ربات جستجو تصاویر گوگل آن را بررسی کند و در نتایج خود نشان دهد.
برای اینکار به این صورت عمل میکنیم:
User-agent: Googlebot-Image
Disallow: /mypic
ربات Googlebot-Image وقتی به این دستور میرسد، اولا متوجه میشود که باید گوش به فرمان باشد چرا که اسم آن صدا زده شده است، در خط دوم هم متوجه میشود که فولدری به نام mypic در مسیر ریشه سایت شما قرار دارد که نباید آن را بررسی کند.
اما سایر رباتها وقتی به این دستور میرسند هیچ توجهی به آن نمیکنند و بدون محدودیت محتوای فولدر mypic سایت شما را هم بررسی میکنند چرا که محدودیت شما تنها مربوط به ربات Googlebot-Image میشود و نه تمام رباتها.
دستور Allow
دستور Allow در بیشتر موارد برای مشخص کردن یک مورد استثنا بکار میرود. برای درک بهتر بگذارید که به سراغ مثال قبلی برویم،
فرض کنید که در این فولدر mypic یک تصویر به خصوص به نام logo.png وجود دارد که دوست دارید استثنا در نتایج گوگل ظاهر شود و توسط ربات Googlebot-Image بررسی شود. در این حالت به این صورت عمل میکنیم:
User-agent: Googlebot-Image
Disallow: /mypic
Allow: /mypic/logo.png
ربات Googlebot-Image وقتی به این دستور میرسد متوجه میشود که علارقم اینکه نباید محتوای فولدر mypic را بررسی کند اما استثنا یک فولدر به نام logo.png در آن وجود دارد که باید آن را بررسی کند.

یک مثال دیگر،
فرض کنید که قصد دارید که دسترسی تمام رباتها را به سایتتان ببندید به جز ربات Googlebot در این حالت هم میتوانیم از دستور Allow استفاده کنیم، برای اینکار ابتدا باید به تمام رباتها بگوییم که نباید محتوای سایتمان را بررسی کنند، برای اینکار به این صورت عمل میکنیم:
User-agent: *
Disallow: /
به کمک این دو خط به ظاهر ساده دسترسی تمام رباتها به سایتمان محدود میشود!
اما همانطور که گفتیم میخواهیم استثنا به ربات Googlebot اجازه بررسی سایتمان را بدهیم برای همین به این صورت عمل میکنیم:
User-agent: Googlebot
Allow: /
این دو خط اما اجازه بررسی سایت ما را به صورت استثنا به ربات Googlebot میدهد.
دستور Sitemap
sitemap یا نقشه سایت یک فایل عمدتا XML است، وظیفه راهنمایی و هدایت رباتهای موتورهای جستجو برای خزش بهتر محتوای سایتها را بر عهده دارد. میتوانیم به کمک فایل robots.txt مشخص کنیم که آدرس این فایل دقیقا کجاست و موتورهای جستجو از کجا باید آدرس نقشه سایت ما را پیدا کنند.
برای اینکار به این صورت عمل میکنیم:
Sitemap: https://example.com/sitemap_index.xml
اما نباید فراموش کنید که اگرچه میتوان سایت مپ در داخل فایل ربات سایت به رباتهای موتور جستجو گوگل معرفی کرد اما این روش بهترین روش معرفی سایت مپ به رباتهای گوگل نیست.
بهترین روش برای انجام اینکار معرفی آدرس نقشه سایت در داخل گوگل سرچ کنسول است. برای انجام اینکار پیشنهاد میکنیم که حتما مقاله “صفر تا صد نقشه سایت” را مطالعه کنید.
گذاشتن کامنت در فایل robots.txt
گاهی اوقات با بزرگ شدن فایل ربات لازم میشود که یادداشتهایی برای خودمان بگذاریم تا بعدا خیلی سریعتر متوجه کارهایی که قبلا انجام دادهایم شویم و ضریب خطا هم کاهش پیدا کند.
برای گذاشتن کامنت و یادداشت در داخل فایل ربات میتوانیم از علامت # استفاده کنیم، به این ترتیب جلوی هشتگ هرچیزی که بنویسیم توسط رباتها و خزندهها نادیده گرفته میشود.
چند نکته که اگر به آنها توجه نکنید خرابکاری میکنید!
حالا که با مهمترین دستورات مورد نیاز در فایل robots آشنا شدید، بد نیست نکاتی را یادآور شویم که خیلی از وبمستران به اشتباه انجام میدهند و همین اشتباهات کوچک اتفاقات خیلی بدی را در سئو سایت آنها رقم میزند.
رباتها به کوچک یا بزرگ بودن دستورات حساس هستند
اولین و مهمترین نکته حساس بودن رباتها و خزندهها به کوچک یا بزرگ بودن حروف است.
به عنوان مثال فولدری به نام Mypic با فولدری با نام mypic برای رباتها متفاوت است و اگر در کوچکی یا بزرگی حروف دقت کافی به خرج ندهید ممکن است فایلها و آدرسهایی را از دسترس خارج کنید که اصلا وجود خارجی ندارند و یا اشتباها یک فولدر و یا فایل دیگر را محدود کنید که دلخواه شما نیست.
آدرسهایی که در فایل robots.txt وارد میکنید همگی باید به صورت نسبی باشند
آدرس دهی در فایل robots به صورت نسبی است، یعنی برای مشخص کردن ریشه وبسایتتان بجای https://example.com/ تنها کافی است که از / خالی استفاده کنید. یا اگر نیاز دارید یک فولدر به نام assets را محدود کنید باید به صورت
Disallow: /assets
عمل کنید و دستور زیر اشتباه است،
Disallow: https://example.com/assets
اگر میخواهید یک فایل خاص را محدود کنید پسوند آن را فراموش نکنید
در صورتی که قصد محدود کردن یک فایل خاص را دارید نباید فراموش کنید که حتما باید پسوند فایل را هم ذکر کنید. به عنوان مثال اگر لازم است که فایل PDF به نام seo را که در ریشه سایتتان قرار دارد، محدود کنید حتما باید نام این فایل را به صورت کامل همراه با پسوند آن ذکر کنید، به این صورت:
Disallow: /seo.pdf
شناخت محدودیتهای فایل robots.txt
قبل از اینکه بخواهیم در فایل robots.txt سایتمان تغییراتی ایجاد کنیم، لازم است که با محدودیتهای این فایل آشنا باشیم.
چرا که ممکن است بتوانیم از طریق دیگری به خواستهای که به دنبال آن هستیم برسیم و از روشهای دیگری برای پنهان کردن صفحات سایتمان در نتایج موتورهای جستجو استفاده کنیم.
برخی از موتورهای جستجو، از دستورات فایل robots.txt پیروی نمیکنند
تمام دستورات و محدودیتهایی که در فایل robots سایتمان ایجاد میکنیم تنها زمانی اعتبار دارند که رباتهایی وجود داشته باشند که به این دستورات احترام بگذارند و از آنها پیروی کنند.
برخلاف رباتهای موتور جستجو گوگل، برخی از موتورهای جستجو دستورات موجود در فایل robots.txt را نادیده میگیرند.
در این حالت، برای جلوگیری از نمایش صفحات سایتمان در این موتورهای جستجو باید به کمک روشهای مسدودسازی مثل گذاشتن پسورد بر روی صفحاتی که نمیخواهیم به کاربران نمایش داده شوند، دسترسی آنها به این صفحات خاص را از بین ببریم.
همچنین بهتر است دستورالعملهای هر موتور جستجو را بخوانید تا مطمئن شوید دستوراتی که مینویسید برای همه موتورهای جستجو کار میکنند.
رباتهای مختلف، دستورات را به روشهای متفاوتی تفسیر میکنند
حتی اگر تمام رباتهای موجود در اینترنت هم به محدودیتهای فایل robots.txt احترام بگذارند، باز هم ممکن است مشکلاتی به وجود بیاید، چرا که ممکن است هر کدام از این رباتها، نحوه تفسیر متفاوتی از دستورات داخل فایل ربات سایت شما داشته باشند و این دستورات معانی متفاوتی برای رباتهای مختلف داشته باشند.
همچنین برخی از دستورات انحصاری رباتهای خاص هم برای بسیاری از رباتها، ناشناخته و غیر قابل درک است و به همین خاطر ممکن است برخی رباتها از این دستورات پیروی کنند و برخی دیگر به آنها توجهی نکنند. دقیقا همانطوری که حرف زدن به زبان چینی برای بسیاری از مردم جهان کاملا غیر قابل مفهوم و درک است.
ایندکس گوگل به فایل ربات سایت احترام زیادی نمیگذارد
اگرچه گوگل صفحاتی که در فایل Robots.txt محدود شدهاند را خزش و ایندکس نمیکند، اما ممکن است از سایر صفحات، لینکهایی به این صفحات محدود شده وجود داشته باشند که موجب ایندکس شدن این صفحات شوند.
به این ترتیب علارقم اینکه شما صراحتا در فایل ربات خود از گوگل خواستهاید که این صفحات را بررسی و ایندکس نکند، اما باز هم مشاهده میکنید که این صفحات در نتایج گوگل ظاهر میشوند.
علاوه بر این، چون رباتهای گوگل اجازه کش کردن محتوای داخل این صفحات را هم ندارند، این URLها به صورت زیر در صفحه نتایج گوگل ظاهر میشوند.
برای جلوگیری از این مشکل، بهتر است از تگ noindex در هدر همان صفحاتی که علاقهای به حضور آنها در نتایج گوگل ندارید استفاده کنید و یا با گذاشتن رمز و یا سایر روشهای بلاک کردن، از ایندکس شدن این URLها جلوگیری کنید.
ساخت فایل robots.txt برای سایت
قبل از ساختن یک فایل robots.txt جدید ابتدا باید اطمینان حاصل کنیم که سایتمان دارای این فایل نیست، برای این تنها کافیست که به انتهای آدرس وبسایتتان robots.txt/ را اضافه کنید، به این صورت:
https://example.com/robots.txt
اگر بعد از وارد کردن این آدرس با یک صفحه ناموجود مواجه شدید این فایل در سایت شما وجود ندارد اما اگر بعد از وارد کردن آن با یک صفحه با دستوراتی که تا به اینجا با آنها آشنا شدیم مواجه شدید، یعنی این فایل در سایت شما موجود است و تنها کاری که لازم است انجام دهید اصلاح و انجام تغییرات موردنیازتان است.
برای انجام تغییرات در این فایل تنها کافیست به ریشه هاست سایتتان مراجعه کنید و دنبال فایلی به نام robots.txt بگردید، سپس میتوانید به کمک ادیتور آنلاین و یا آپلود یک فایل جدید، فایل robots.txt جدیدتان را جایگزین قبلی کنید.
اما در صورتی که این فایل را پیدا نکردید و در آدرس robots.txt/ هم با یک صفحه ناموجود رو به رو شدید، تنها کاری که لازم است انجام دهید، ایجاد یک فایل جدید با پسوند txt و آپلود آن بر روی ریشه اصلی وبسایتتان است.
توجه: رباتها و سایر خزندهها به بزرگی و کوچکی حروف فایل ربات شما حساس هستند و فقط و فقط باید نام به این فایل را به صورت robots.txt وارد کنید و نامهای مانند Robots.txt و … اشتباه هستند و توسط خزندهها نادیده گرفته میشوند.
ساخت و ویرایش فایل robots.txt در سایتهای وردپرسی
برخی از سیستمهای مدیریت محتوا همانند وردپرس، به صورت خودکار اقدام به ایجاد فایل robots.txt میکنند. به این معنی که اگر شما به ریشه هاست سایت خودتان مراجعه کنید فایلی تحت عنوان robots.txt را پیدا نخواهید کرد. بلکه این فایل به صورت مجازی و خودکار توسط وردپرس ایجاد میشود.
محتوای این فایل مجازی هم به صورت پیشفرض به این صورت است:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
درصورتی که شما اقدام به ایجاد یک فایل حقیقی به نام robots.txt در ریشه هاست سایت خودتان کنید، فایل ربات مجازی به صورت خودکار از کار میافتد و فایل حقیقی آپلود شده توسط شما جایگزین آن خواهد شد.
با اینحال در سیستم مدیریت محتوا وردپرس به لطف پلاگینهای مختلف که برای آن طراحی شده است، کار حتی از این هم راحتتر است.
در ادامه نحوه بروزرسانی و انجام تغییرات در داخل فایل robots.txt را در دو پلاگین یواست (Yoast) و رنک مت (Rankmath)، بررسی خواهیم کرد.
ویرایش فایل ربات سایت توسط افزونه سئو یواست (Yoast SEO)
درصورتی که از افزونه یواست برای سئو سایت وردپرسی خود استفاده میکنید، این افزونه برای مدیریت و ویرایش فایل ربات سایتتان یک بخش ویژه را در نظر گرفته است.
برای ویرایش این فایل، کافیست به از بخش سئو > گزینه ابزارها را انتخاب کنید.
در پنجره جدید باز شده، گزینه ویرایش پرونده را انتخاب کنید.
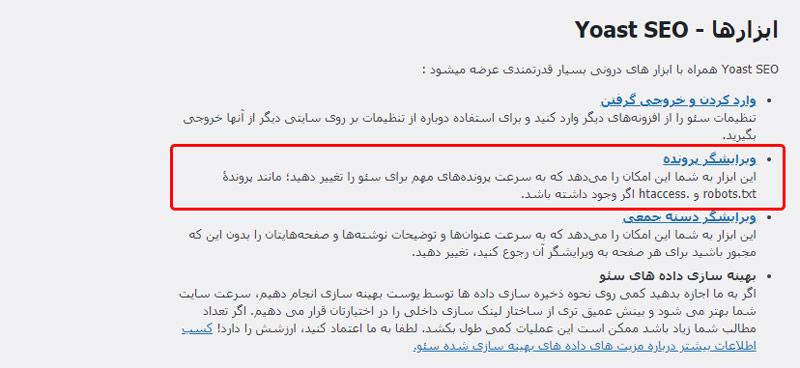
در این قسمت شما میتوانید دو فایل اصلی و مهم robots.txt و htaccess. سایت خودتان را ویرایش کنید.
در صورتی که از قبل به کمک این پلاگین یک فایل robots.txt هم برای سایتتان ایجاد نکرده باشید به صورت زیر به شما پیشنهاد ایجاد یک فایل جدید میدهد که باید بر روی آن کلیک کنید.
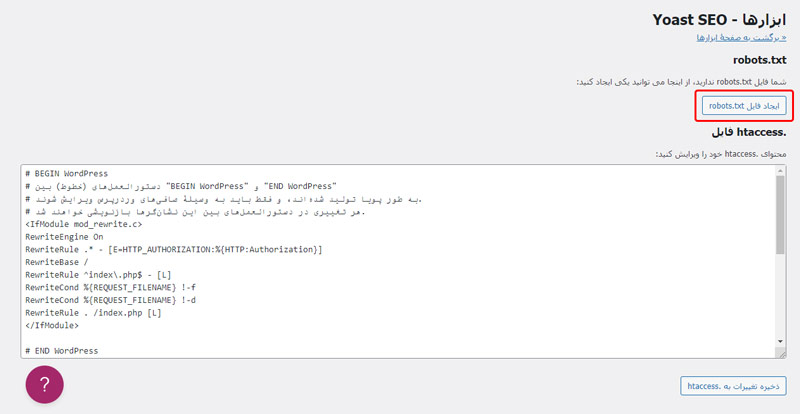
در نهایت بعد از انجام تغییرات خود میتوانید بر روی گزینه ذخیره تغییرات در robots.txt کلیک کنید تا تغییرات شما ذخیره شوند.
ویرایش فایل ربات سایت توسط افزونه سئو رنک مت (RankMath SEO)
افزونه رنک مث هم که به تازگی به یکی از رقبای جدی پلاگین یواست تبدیل شده، برای ویرایش مستقیم فایل robots.txt بخشی را در نظر گرفته است.
برای انجام این کار تنها کافیست از بخش Rank Math > گزینه تنظیمات عمومی را انتخاب کنید.
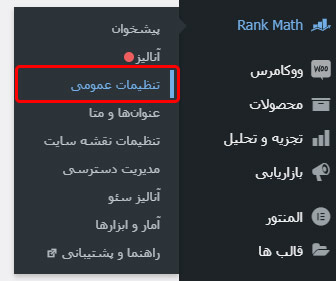
در پنجره جدید باز شده، از منو کناری بر روی گزینه ویرایش robots.txt کلیک کنید.
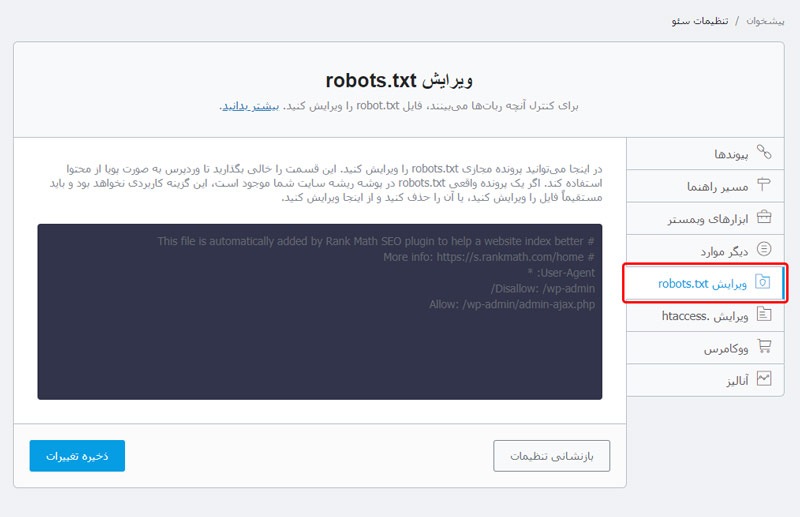
حالا به راحتی میتوانید محتوای فایل ربات خود را ویرایش کنید و بعد از انجام تغییرات بر روی گزینه ذخیره تغییرات کلیک کنید.
تست فایل robot و اطمینان از سالم بودن آن
بعد از ایجاد و یا انجام اصلاحات در فایل ربات، باید از صحت تغییرات خود مطمئن شوید. بهترین روش برای اینکار استفاده از ابزار تست فایل robots.txt گوگل سرچ کنسول است.
اگر وبسایت خود را به ابزار گوگل سرچ کنسول متصل کرده باشید، وقتی که ابزار تست را باز کنید از شما درخواست میکند که Property مورد نظرتان را انتخاب کنید.
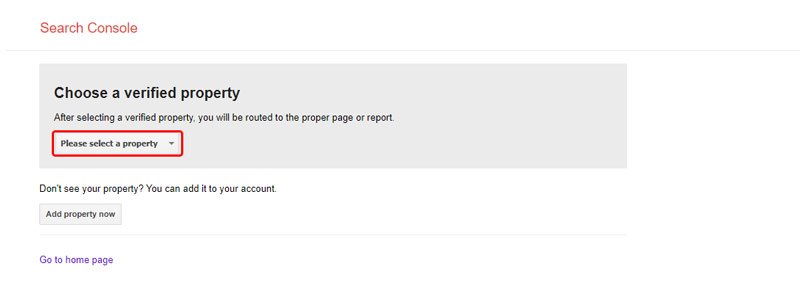
بعد از انتخاب، صفحهای باز میشود که در آن گوگل آخرین فایل ربات پیدا شده از سایتتان را به شما نمایش میدهد.
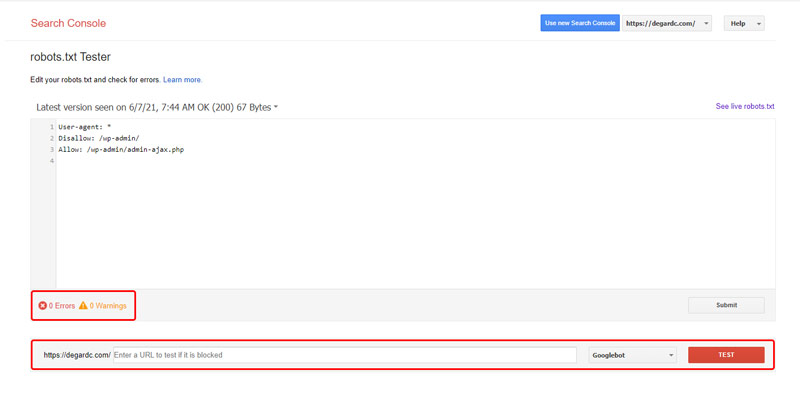
در این قسمت شما میتوانید به صورت زنده تغییرات مورد نظرتان را در محتویات فایل robots.txt انجام دهید و سپس از طریق بخش پایینی بررسی کنید که آیا تغییرات انجام شده دقیقا همان چیزی هستند که به دنبال آن هستید یا خیر.
همچنین در قسمت Errors و Warnings هم خطاها و هشدارها لازم به شما داده خواهد شد که باید به آنها دقت کنید.
بعد از انجام تغییرات، میتوانید محتویات این صفحه را کپی کنید و یا به صورت یک فایل robots.txt دانلود کنید و جایگزین فایل قبلی خود کنید. اما فراموش نکنید که محتویات این صفحه به صورت آزمایشی است و تا زمانی که تغییرات در فایل اصلی robots.txt در سایت شما انجام نشود تاثیری نخواهند گذاشت!
کی باید در فایل robots.txt تغییرات بدیم؟
استفاده از فایل robots.txt برای تمام سایتهای متوسط و بزرگ تقریبا اجتناب ناپذیر است. اما در برخی سایتهای کوچک با تعداد صفحههای محدود، میتوان در مواردی حتی قید این فایل را هم زد و به موتورهای جستجو اجازه داد تا تمام صفحات را بررسی کنند.
اگر صاحب یک وبسایت کوچک با تعداد صفحات کمی هستید، با مراجعه به سرچ کنسول وبسایتتان میتوانید تعداد صفحاتی از سایتتان که توسط گوگل ایندکس شدهاند را در بخش Coverage مشاهده کنید.
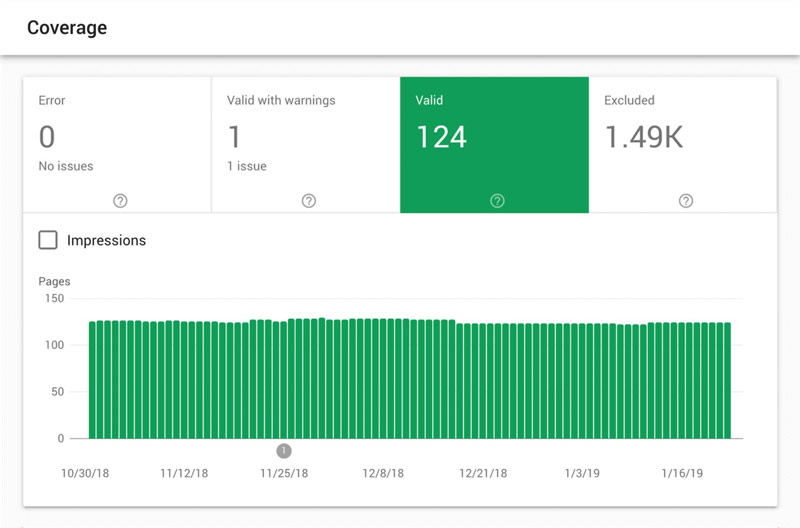
اگر تعداد صفحات ایندکس شده چیزی فراتر از تصور و انتظارتان بود در این حالت احتمالا به یک فایل robots.txt با قوانین و محدودیتهای مشخص نیاز دارید.
اما اگر تعداد صفحات ایندکس شده دقیقا و یا تقریبا همان تعداد صفحاتی بود که انتظار دارید در داخل گوگل ایندکس شده باشند، نیازی به ساخت و یا تغییر فایل robot سایت خود ندارید.
معمولا یکبار قوانین و محدودیتهای فایل robot مشخص میشود و تا زمانی که محدودیتهای این فایل مشکل ساز نشدهاند نیازی به اصلاح و تغییر فایل robots.txt نیست.
مراقب فایل robots.txt سایتتان باشید
در این مقاله به طور کامل با فایل ربات سایت و نحوه ساخت و بررسی آن آشنا شدیم. دیدیم که این فایل در سئو سایت شما نقش بسیار کلیدی و مهمی را بازی میکند و یک تغییر کوچک و کم اهمیت میتواند تاثیر بسیار زیاد و بزرگی بر روی نحوه رفتار خزندههای موتور جستجو گوگل با صفحات سایت شما و به طور کلی سئو سایتتان ایجاد کند.
به همین خاطر و بخاطر سایر مسائل امنیتی، همیشه توصیه میشود که هرچند وقت یکبار، صحت و سلامت فایل ربات سایتتان را بررسی کنید و از دستوراتی که داخل این فایل وجود دارد اطمینان حاصل کنید.
در پایان اگر سوالی در خصوص فایل robots.txt و مسائل مرتبط با آن دارید حتما مطرح کنید و به غنیتر شدن محتوای این مقاله کمک کنید. سوالات شما در کمتر از 24 ساعت پاسخ داده خواهند شد.
شنیدن تجربیات ارزشمند شما در خصوص این مقاله هم خواندن آن را دوچندان جذابتر خواهد کرد، حتما تجربیات و نظراتتان را با سایر کاربران درمیان بگذارید!








6 پاسخ
سلام وقتتون بخیر، برای نو ایندکس کردن صفحات سرچ کوئری، چه کدی باید در robots.txt زده بشه؟
سلام، میتونید از علامت ستاره (*) برای استثنا کردن تعداد زیادی صفحه استفاده کنید، به عنوان مثال دستور *?disallow: /search تمام صفحات سرچی که توشون از URL Parameter ها استفاده شده رو مستثنی میکنه، اما ی نکتهای که توی مقالهام بهش اشاره شده اینه که گوگل تضمینی بابت نوایندکس کردن صددرصد این صفحهها به شما از طریق فایل ربات نمیده و حتی با مستثنی کردنشون هم ممکنه باز کراول بشن، راه حل بهتر برای جلوگیری از کراول و ایندکس کردن اینجور صفحات اگر دسترسی به کدهای سایتتون دارید استفاده از تگ هد noindex تو صفحاتی هستش که توشون از پارامترها استفاده شده.
تگ noindex رو چطور برای پارامتر بنویسیم؟
برای disallow کردن url parameter ها میتونید از دستور زیر استفاده کنید
Disallow: /*?param1=*¶m2=*¶m3=*
و به همین ترتیب اگر پارامتر خاصی هست که میخواید بررسی بشه میتونید از دستور allow استفاده کنید و دقیقا مثل بالا اون پارامترهای خاص رو اجازه بررسی بهشون بدید
جز این روش، به کمک x-robots-tag هم میشه اینکارو کرد برای اطلاعات بیشتر پیشنهاد میکنم مقاله زیر رو هم مطالعه کنید
https://yoast.com/x-robots-tag/
منظورم رو درست نرسوندم
گفتید چطور کوئری ها رو خزش نکنه ولی نگفتید چطور ایندکس هم نکنه. کلی گزارش نوایندکس درست شده تو کنسول چطور رفع کنم؟؟
مثلا صفحه سبد یا پرداخت یا کوئری add-to-cart رو دیسلو میکنیم کلی گزارش نوایندکس تو کنسول پر میشه. چون بازم داره کرال باجت هدر میده. درسته؟
سلام، اولین نکته اینه که در مورد کراول باجت خیلی حساس نباشید (کراول باجت در مورد کیس هایی که چندین هزار صفحه الکی دارن که این صفحات دارن کراول میشن خیلی مهمه و در حد چند ده تا یا حتی چند صدتا صفحه تاثیر خاصی رو سئو سایت شما و کراول باجتتون نداره)
کراولرهای گوگل عموما از دو روش صفحات رو پیدا میکنن و کراول میکنن: لینک ها، فایل ربات سایت
بهترین روش برای جلوگیری از کراول صفحات سایت هم تنظیم درست فایل ربات سایته، اما ممکنه به قول خودتون شما یک صفحه رو disallow کنید اما بازم ببینید که توی سرچ کنسول بهتون خطا Excluded by ‘noindex’ tag داده، دلیل این اتفاق اینه که اون صفحات خاص (که تقریبا در تمام سایت های وردپرسی صفحات cart و checkout جزو همین صفحاتن) یکسری لینک داخلی (یا حتی ممکنه خارجی) داشته باشند و همین لینکها باعث میشن که کراولرهای گوگل علارغم اینکه از محتویات فایل robots.txt شما آگاهن، بازم به سراغ این صفحات بیان.
دلیلشم اینه که این صفحات بهشون لینک وجود داره و گوگل برای تکمیل اطلاعاتش نسبت به صفحه مبدا لینک (و نه صفحه مقصد) مجبوره که صفحات مقصد لینک رو هم بررسی کنه و به همین خاطره که به شما هشدار میده که آیا حواستون هست که این صفحات noindex شدن؟! اگرم دقت کرده باشید توی سرچ کنسول با رنگ خاکستری این هشدارهارو نشون میده و رنگ قرمز براشون انتخاب نشده (که معنیش اینه که اینا خطا نیستن صرفا یکسری هشدار از سمت گوگلن و معنی اشتباه یا خطا ندارن)
نکته آخرم اینه که با تغییر فایل ربات سایت شما چندین ماه طول میکشه تا خطاهای سرچ کنسولتون، مخصوصا در این مورد خاص کمتر بشه.
امیدوارم توضیحات کامل بوده باشه و به جوابتون رسیده باشید.